Audio Examples of paper: A Vocoder Based Method For Singing Voice Extraction
Pritish Chandna, Merlijn Blaauw, Jordi Bonada, Emilia Gómez
Music Technology Group, Universitat Pompeu Fabra, Barcelona
Examples From iKala Validation Set (In Mandarin Chinese)
These are examples from the iKala dataset, on which the system was trained and evaluated
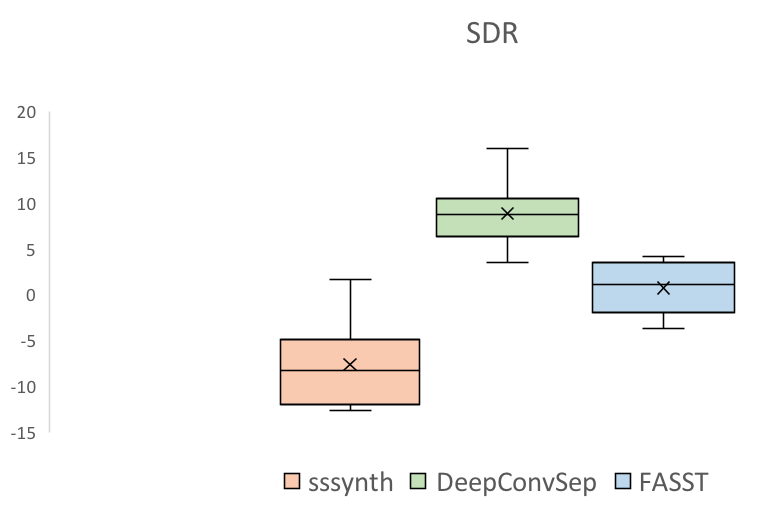
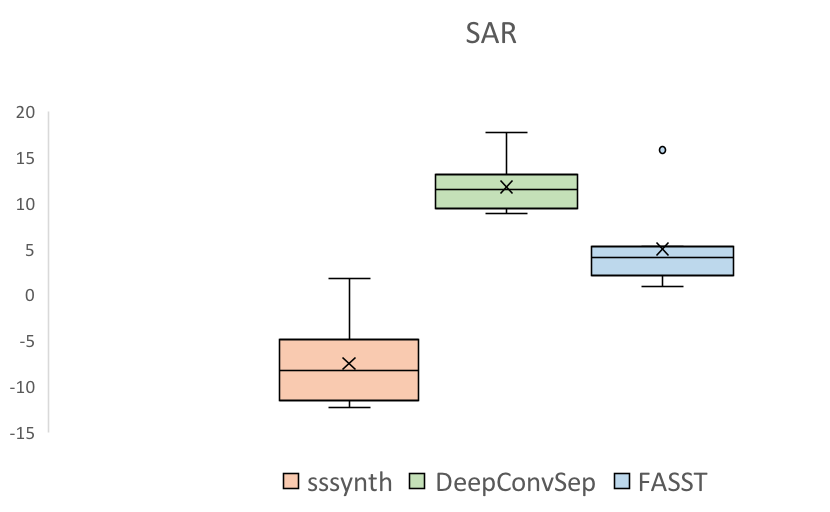
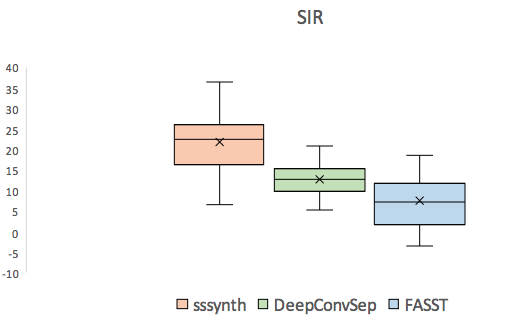
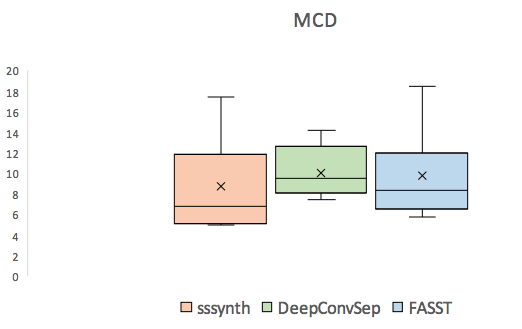
| Mixture | Original vocals | Vocals extracted using sssynth | Vocals extracted using DeepConvSep [1]. | Vocals extracted using FASST [2]. | |
| 21084_verse |
| Mixture | Original vocals | Vocals extracted using sssynth | |
| MusicDelta_Reggae |
|
|
|
|
[1] P. Chandna, M. Miron, J. Janer, and E. Gómez, “Monoaural audio source separation using deep convolutional neural networks” International Conference on Latent Variable Analysis and Signal Separation, 2017.
[2] A. Ozerov, E.Vincent, and F. Bimbot, “A general flexible framework for the handling of prior information in audio source separation,”IEEETransactions on Audio, Speech, and Language Process-ing, vol. 20, no. 4, pp. 1118–1133, 2012.
[3] R. Bittner, J. Salamon, M. Tierney, M. Mauch, C. Cannam and J. P. Bello, "MedleyDB: A Multitrack Dataset for Annotation-Intensive MIR Research", in 15th International Society for Music Information Retrieval Conference, Taipei, Taiwan, Oct. 2014.